

恒华分布式数据库系统
一、概述
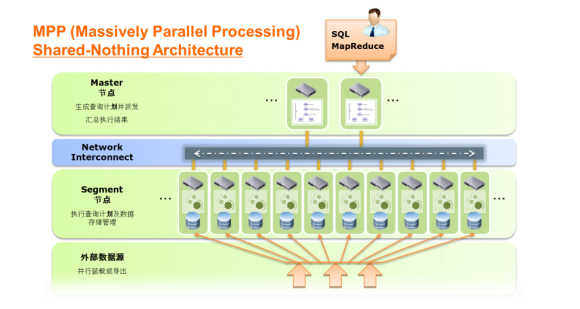
恒华分布式数据库系统是业内首创的无共享、大规模并行处理(massivelyparallel processing (MPP))的数据库软件产品,它包含大规模并行计算技术和数据库技术最新的研发成果:包括无共享/MPP,按列存储数据库,SQL LLVM JIT编译运行,数据库内压缩,永不停机扩容,多级容错,JSON类型等等。该数据库软件被业界认可为扩展能力最大的分析型(OLAP)数据库软件。
二、恒华分布式数据库系统分布式数据仓库软件特性介绍
恒华分布式数据库系统是业界首创将大规模并行计算技术,应用到了数据库软件领域。该类技术同样应用在Google搜索引擎的中。
1、恒华分布式数据库系统数据仓库软件功能:
无共享/MPP核心架构
恒华分布式数据库系统将数据平均分布到系统的所有节点服务器上,所以节点存储每张表或表分区的部分行,所有数据加载和查询都是自动在各个节点服务器上并行运行,并且该架构支持扩展到上万个节点。

SQL LLVM JIT编译运行
恒华分布式数据库系统发明SQL使用LLVM编译器即时编译运行(LLVM JIT),这样的SQL编译运行大大加快复杂SQL的运行速度,它比GPDB和其他传统关系数据库的准解释执行速度快20-2倍。


混合的存储和执行(按列或按行)
恒华分布式数据库系统发明支持混合按列或按行存储数据,每张表或表分区可以由管理员根据应用需要,分别指定存储和压缩方式。
基于这个功能,用户可以对任何表或表分区选择按行或按列存储数据和处理方式。这些是在建表或表分区的DDL语句中配置的,只需在建表或表分区时指定:这个功能基于多态维数据存储技术。


多层次的容错能力
恒华分布式数据库系统自己包含多层次容错和冗余能力,这是云计算架构软件的一个重要特征。该功能保证整个数据仓库系统在遇到硬件、软件的故障的情况下,仍然自动继续运行。
在线系统扩容(永不停机)
在系统中增加节点服务器即可增加存储容量,处理性能和加载性能。当系统扩展时,数据仓库保持在线,并且完全可用,扩展进程在后台运行。增加节点服务器,性能和容量线性增加。
负载管理(Workload Management)
具有系统资源管控能力,并且可控制给各个查询分配各自系统资源。允许管理员指派资源队列,从而管理数据仓库的队列进入执行情况。在运行的查询的优先级可以随时调整。

并行数据装载能力
基于MPP Scatter/Gather流技术的高性能并行加载功能。加载速度随着节点线性增加,实际超过100MB/节点机/秒。

灵活的外部数据访问
数据仓库软件可在任意外部数据源上并行运行常规SQL,不论外部数据源的位置,格式或存储介质。并且支持Hadoop HDFS文件系统的直接读写访问。
数据库内压缩
利用业界领先的lz4压缩技术,进一步提高性能,并极大地节省了数据存储空间。用户可获得3-30倍的空间节省,并且同时获得相应有效I/O性能提升。
多层次表分区能力
允许灵活地按照时间、范围、值域划分表分区。表分区由DDL设定,分区层级不限。数据仓库软件的查询优化器自动从查询执行计划中略去不涉及的表分区。
索引功能
恒华分布式数据库系统支持各种数据库索引技术,包括B-Tree,Bitmap等等。按列存储、按行存储数据库表都支持索引。
支持JSON及完全遵从SQL最新标准
恒华分布式数据库系统支持JSON格式。它还遵从SQL-92 , SQL-99 ,至SQL 2008标准,并包括SQL 2008 OLAP扩展项,如Cube, Window, Cursor, CTE。所有SQL及PL/SQL查询都是在系统上并行执行。
支持SQL 2008 OLAP 扩展标准及Oracle SQL特性兼容
对SQL语言包括其OLAP扩展标准,都是在恒华分布式数据库系统实现并行执行。全面支持SQL 2008 OLAP标准,包括Window 函数,Rollup,Cube等等。支持兼容Oracle的SQL特性。
客户端访问及第三方工具支持
完全支持数据库技术接口标准,例如: SQL, ODBC, JDBC, OLEDB,SAS,MATLab,R语言,MADLib等。同时,广泛地支持各个BI和ETL软件工具,如Cognos, SAS, Pentaho, Tableau, SAP BO。
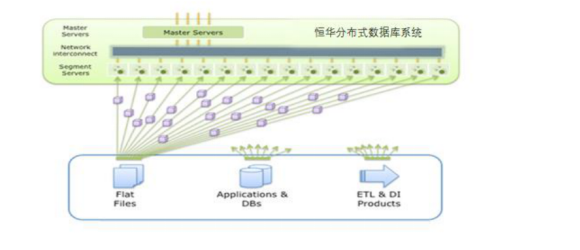
2、与Hadoop HDFS 协同工作
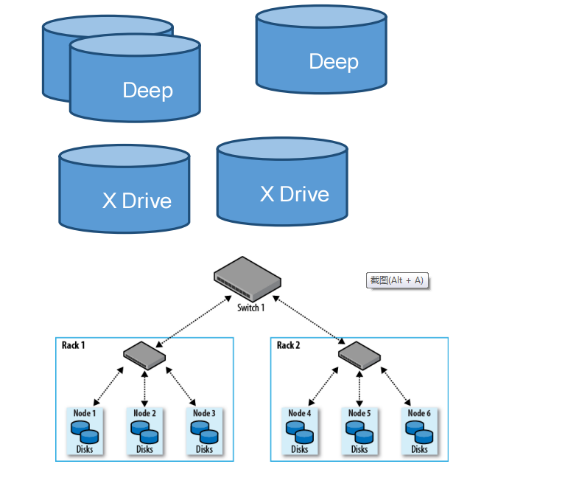
X Drive:恒华分布式数据库系统与外部数据接口
•恒华分布式数据库系统 MPP 可通过 X Drive 读取外部数据
•可无缝外接 NFS, HDFS, 等
• 部分执行计划的下推
• 减少网络数据传输,提高性能
• 与恒华分布式数据库系统优化器紧密结合,统一考虑 X Drive 中的数据和恒华分布式数据库系统中的数据。
• 可分离独立扩展
• 通过 HDFS 增加存储容量
• 通过增加 X Drive 来扩展网络带宽
• 增加恒华分布式数据库系统集群或集群中的结点来增加复杂分析过程中的计算能力
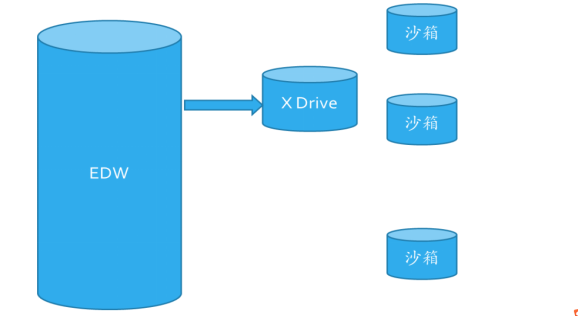
X Drive 应用场景一
• EDW 数据一次抽取到 Xdrive 中,易管理,存储开销小。
• X Drive 中的数据无需 ETL 进入沙箱。 查询时计算下推至 X Drive。
• 多个数据科学家使用不同的小集群或沙箱,自由度高,无干扰。共享 X Drive 中的数据。
• 完成试验后,新的模型仍可以直接返回到 EDW 中,研发成本可控。

X Drive 应用场景二
• DW 运行生产环境。
• 非/半结构化数据存在 HDFS 中。
• 常见问题:
• EDW 无法同时查询数仓和 HDFS 中的数据,或性能低
• 若 ETL 过程,将数据导入 EDW, 比较慢,开销大。


X Drive 应用场景三
• 恒华分布式数据库系统运行生产环境。
• 非/半结构化数据存在 HDFS 中。
• 恒华分布式数据库系统通过 Xdrive 读取 HDFS 数据
• 存储,网络,和计算独立扩展
• 技术关键在恒华分布式数据库系统与 X Drive 紧密结合,保证高性能和扩展性

X Drive 应用场景四
• 恒华分布式数据库系统通过 X Drive,将数据存放在 NFS 或 HDFS 中。恒华分布式数据库系统中仅有 meta data。
• 由于恒华分布式数据库系统轻量, 可在云上快速部署,迁移。
• 有些部署,生产环境在云下,但数据科学家的沙箱在云上。 可以通过 X Drive 实现云上云下的数据交换。


综上所述,恒华分布式数据库系统数据仓库软件技术构成如下图:





